
Après vous avoir présenté une introduction aux produits data, l’importance du Product Management dans leur développement et les différents profils nécessaires pour un tel projet, voici quelques notions qui vous aideront à vous sentir à l’aise dans vos échanges avec des profils data, notamment sur une première expérience de Data Product Management. Nous vous présentons une liste non-exhaustive de termes que nous avons rencontrés dans nos missions. Et si vous en croisez d’autres (et ce sera le cas), n’ayez pas peur de poser des questions, cela mettra en avant votre curiosité et votre intérêt pour le travail de vos collaborateurs. trices.
Features, biais, outliers, overfit : un petit mémo de vocabulaire Machine Learning
Modèle
Un modèle de Machine Learning crée une correspondance entre un ensemble de données d’entrée et une variable cible.
L'objectif est que le modèle apprenne un mapping entre ces entrées et la variable cible. Alors, avec de nouvelles données (où la cible est inconnue), le modèle est capable de prédire avec précision la variable cible.
Le Machine Learning se base sur des fonctions mathématiques qui, par itération et alimentation de nouvelles données, permettent de créer des algorithmes performants. Ces algorithmes d’apprentissage sont entraînés avec une large quantité d’exemples pour obtenir un modèle.
Il existe différents types d’algorithmes : supervisés ou non supervisés, de classification ou de régression.
Quelques exemples d’algorithmes fréquemment utilisés : decision trees, random forest, neurals networks, K-means, SVM (Support Vector Machine) …
📚 Lire notre article “Data Product Management (1/4): introduction aux produits data”
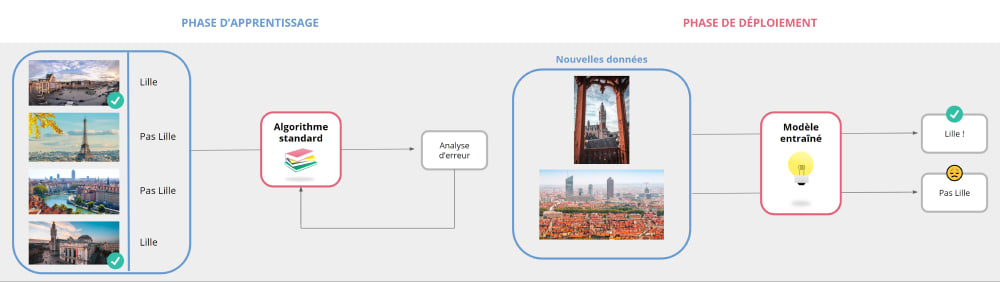
Illustration d’un modèle de Machine LearningSource : Hubvisory
Feature ou Variable d’intérêt
Une variable est une propriété mesurable de l'objet/phénomène que vous analysez. Et une variable d’intérêt souvent appelée feature dans le langage quotidien des profils data est une variable sélectionnée (et parfois transformée) parmi toutes les variables disponibles.
En effet, un modèle repose toujours sur une liste de variables qui sont issues de données d’entrée brutes reformatées, traitées, enrichies ou calibrées.
Par exemple, vous souhaitez prédire le désintérêt d’un utilisateur pour votre produit (exemple : Netflix). La variable cible est la résiliation d’un abonnement (elle peut avoir pour valeur oui ou non) et les variables d’intérêt sont par exemple le nombre et le type de contenus visionnés, les séries ou films entamés mais non terminés, la fréquence des connexions… L’analyse de ces variables d’intérêt ou features va permettre la prédiction.
Autre exemple, pour notre modèle de reconnaissance de la plus belle ville du monde (présenté dans l’article 1/4), les variables d’intérêt ou features tirées des photos fournies peuvent être la luminosité, la couleur des bâtiments, leur forme, la présence ou non d’une bière …
Feature Selection
Lorsqu’on réfléchit à la création d’un modèle, une des premières choses à faire est d’identifier quelles variables doivent être utilisées pour optimiser le développement de ce modèle ? On parle de “Feature Selection”. En effet, il est souvent intéressant de réduire le nombre de variables d’intérêt en supprimant les features inutiles ou celles qui brouillent les résultats.
Cela permet en plus de réduire les coûts du modèle et de le rendre plus simple à interpréter (pas facile d’expliquer les résultats d’un modèle avec 50 variables …).
Cette sélection peut se faire de manière manuelle. Mais en général, elle se fait automatiquement : un algorithme sélectionne les variables les plus importantes et les plus influentes.
Dans les deux cas, une connaissance métier (Product Manager, Business Analyst, UX) permet de mieux comprendre et interpréter les données qui sont utilisées, cela permet de bénéficier d’une certaine intuition des features ou variables importantes.
Biais
Un jeu de données biaisé présente des valeurs implicites humaines et aboutit à un apprentissage faussé et donc biaisé de l’algorithme. Cela peut entraîner une mauvaise performance du modèle, une perte de confiance voire entraîner des conséquences néfastes.
Outliers
Valeurs / données qui se détachent de la moyenne, des autres données (on parle d'aberration).
Définition d’un outlier
Performance d’un modèle : accuracy, recall, précision
Le but du développement d’un modèle de Machine Learning est d’atteindre la meilleure performance possible (avec un degré de justesse le plus élevé par exemple). Sur notre modèle de plus belle ville du monde, on espère que toutes les photos données au modèle seront correctement identifiées comme photo de Lille ou autre ville.
Plusieurs leviers permettent de jouer sur cette performance, par exemple :
- le choix de l’algorithme
- la quantité et la qualité des données d’entrée
- les variables d’intérêt sélectionnées
Plusieurs indicateurs sont suivis par les équipes data lors du développement d’un modèle. L’accuracy par exemple est plutôt simple à comprendre : il indique le pourcentage de bonnes prédictions. Il existe aussi le recall : cet indicateur informe sur la proportion de faux négatifs (on a identifié cette photo comme représentant une autre ville que Lille alors que c’était bien la capitale des Flandres).
Train and test set
Pour s’assurer de la performance d’un modèle (sa capacité à faire les bonnes prédictions sur base de nouvelles données), on met en place des cross validations.
La méthode la plus simple de cross validation est la “holdout method”. On prend un jeu de données (dataset) qu'on va diviser en training set et testing set. Le training set permet d'entraîner l’algorithme et le test set, de juger de sa performance.
Composition d’un dataset d’un produit Machine LearningSource : Hubvisory
Overfit ou surapprentissage
Le surapprentissage est un risque lorsque le modèle a trop appris les particularités des données du training set, autrement dit il s’est “surspécialisé” sur l’échantillon de données qu’on lui a fourni. Cela a pour conséquence que, sur des données réelles qu’il n’a jamais vu, le modèle ne sera pas pertinent.
Deep Learning
Le Deep Learning est un sous-domaine du Machine Learning, c’est une méthode plus récente d’intelligence artificielle qui s’inspire de la manière dont fonctionnent nos cerveaux.
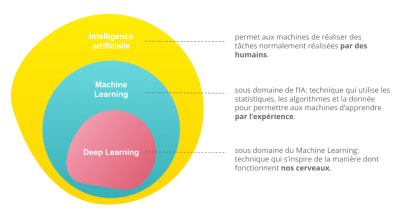
_Lien entre l’intelligence artificielle, le Machine Learning et le Deep Learning_Source : Hubvisory
Nos cerveaux transfèrent des informations vers et depuis des cellules nerveuses : les neurones. Ce sont ces neurones qui traitent et transmettent les informations.
💡 Nouveau savoir à ressortir au prochain AfterWork Produit (c’est cadeau !) : au meilleur de notre forme, nous disposons en moyenne de 86 milliard de neurones.
Le Deep Learning essaie de reproduire ce fonctionnement humain en s’appuyant sur les réseaux de neurones artificiels.
Voici un exemple simplifié pour illustrer. Chaque réseau de neurone se composent de trois types de couche:
- La couche d’entrée (données brutes - les variables) : porte d’entrée des données utilisées.
- Les couches cachées : à chaque couche de ce type, une nouvelle analyse est appliquée aux données de la couche précédente.
- La couche de sortie (la prédiction) : où les données de sorties sont traitées.
Chaque noeud (cercle blanc sur l’illustration) est appelé neurone et c’est là qu’est traitée la donnée. On parle de Deep Learning du fait des couches cachées. Dans notre exemple, nous vous présentons 2 couches cachées mais il existe des réseaux de neurones avec 100 “hidden layers” !
Un même cas d’usage ou besoin utilisateur peut être répondu par un modèle Machine Learning ou un modèle Deep Learning. En général, les modèles de Deep Learning sont plus performants, surtout quand vous disposez d’un volume de données très important mais ils demandent plus de temps à entraîner et requièrent du hardware plus complexe. Ils sont aussi moins facilement interprétables : on peut souvent faire face au “Black Box problem”.
Tous ces éléments sont à avoir en tête en tant que Data Product Manager afin d’aider son équipe à faire le bon choix de modèle selon le contexte.
📚 En savoir plus sur le black box problem
Scikit-Learn
Il existe des librairies d'outils dédiés au Machine Learning et à la Data Science dans l'univers Python, par exemple Scikit-Learn qui est la principale bibliothèque.
Quelques définitions autour des services Cloud
VM (Virtual Machine)
Une VM est un ordinateur dans un ordinateur. Précisons un peu… Un ordinateur ou machine est un équipement électronique capable d’exécuter des instructions programmées. Ces machines sont composées de pièces matérielles qu’on appelle “hardware” (carte mère, disque dur, batterie…). Ces éléments ne sont pas utilisables tel quels par des utilisateurs lambda, les systèmes d’exploitations sont un type de software qui permettent l’utilisation simple des ordinateurs en contrôlant les Hardware d’une machine (exemples : Windows, MAC OS, Linux, Android, IOS …).
Une Machine Virtuelle est un autre type de software : elle permet d’exécuter un autre système d’exploitation dans un système d’exploitation existant. Imaginez que vous utilisez MAC OS sur votre ordinateur mais vous souhaitez utiliser Linux, une machine virtuelle vous le permettra.
Illustration de la Machine VirtuelleSource : Hubvisory
Une même machine physique peut utiliser plusieurs machines virtuelles.
Lors du développement de produits data, les machines virtuelles sont utilisées. En effet, entraîner un modèle requiert beaucoup de ressources, temporairement. Une fois le modèle prêt, cette capacité n’est plus nécessaire, c’est une des raisons pour laquelle il est intéressant d’utiliser des machines virtuelles. Une des missions des équipes data sera d’optimiser leur utilisation : prend-t-on des VM ? combien ? etc …
ETL (Extract Transform Load)
Un ETL fait partie de la boite à outil des profils data : il permet une séquence d’opérations indispensables portant sur les données: collecte de la donnée depuis différentes source (Extract), réorganisation et nettoyage (Transformation) et chargement de ces données prêtes à l’emploi dans leur nouvel emplacement (Load). En effet, la donnée qui est récupérée pour être utilisée en entrée d’un modèle de Machine Learning ou d’un produit de Data Decision est brute, elle peut être inutilisable en l’état.
Ces différentes opérations peuvent être faites “manuellement” via des lignes de code mais il existe des outils qui permettent de faciliter ces étapes (ex: Apache Airflow, pandas, Glue …).
Autour de la donnée (stockée)
Données structurées vs non structurées
La donnée structurée, c’est LE cadeau à faire aux profils data. Il s’agit de données propres et complètes. Toutes les informations sont rangées (structurées) sous des catégories et des champs. Elles sont prêtes à l’emploi, elles peuvent directement être utilisées dans un dashboard ou être envoyées dans un algorithme pour construire un modèle de Machine Learning. La donnée n’est jamais parfaite mais vous voyez l’idée.
Au contraire, la donnée non structurée est brute et inutilisable dans son état. Ces jeux de données ne correspondent pas à un format de modèle de données (exemple : des documents, des images, des fichiers audio, des images de surveillance, les transactions des clients d’un site e-commerce …)
Ce sont bien sûr le type de données les plus abondantes dans les entreprises.
DataLake
Un Data Lake est un espace de stockage partagé global à une organisation ou une entreprise. n temps réel, le DataLake accueille les flux de données des différentes sources de l’entreprise (fichiers de log, analytics du site web, réseaux sociaux…). L’avantage de ce lac de données est qu’il n’impose aucune contrainte de format ou de taille de données, elles arrivent telles quelles dans l’espace de stockage : non structurées, structurées …
Ces données sont alors utilisées par les équipes data qui ont une vision d’ensemble des données à dispo.
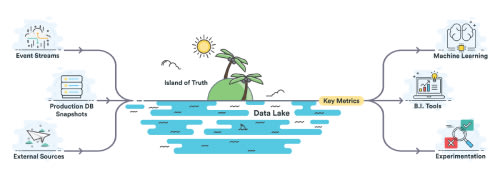
Qu’est-ce qu’un DataLake ?
En conclusion
Nous espérons que ce glossaire vous aura éclairé.e et accompagné.e dans vos premiers pas en tant que Data Product Manager. Encore une fois, cela reste une liste non exhaustive mais qui permet d’éclairer des concepts clés liés au développement de produits data (à succès !).
📚 Lire notre 1er article sur le Data Product Management : "Introduction aux produits data”
📚 Lire notre 2ème article sur le Data Product Management : "Comment appliquer les méthodes du Product Management aux produits data ?"
📚 Lire notre 3ème article sur le Data Product Management “Constitution d'une équipe produit data”
Nous arrivons à la fin de cette série de 4 articles autour du Data Product Management !
Félicitations ! Vous avez tenu le coup. Si vous êtes encore là, c’est que ce domaine vous intéresse (ou vous passionne ?) alors n’hésitez pas à nous faire des retours ou à nous contacter pour échanger de manière plus détaillée sur ces problématiques.


